Contents
이 논문은 2015년 ICLR에서 등장한 논문으로써 처음 번역 분야에 Attention 개념을 사용한 논문으로 알려져있다. NLP분야를 공부하기 위한 필수 관문이라고 생각하기에 리뷰를 시작하려 한다.
paper : Neural Machine Translation by Jointly Learning to Align and Translate
이 리뷰는 pr12 리뷰를 참고하였습니다.
1. Main contributions
논문에서의 메인 아이디어는 다음 두 가지이다.
인코더 : Bidiretional RNN을 적용했다.
- 논문에서는 \(\overrightarrow{h_j^\top}\)와 \(\overleftarrow{h_j^\top}\)를 concatenate하여 인코더의 hidden state로 사용한다.
디코더 : Proposed an extension model(attention network)
- attention mechanism : Hidden states들의 weighted sum을 계산
2. Abstract, Introduction
NMT(Neural Machine Translation)은 machine translation 분야의 최근에 제안된 방식이다. 특히, 최근의 모델들은 encoder-decoder 구조에 속한다. Input 문장을 encoder network을 통해 fixed size vector로 인코딩하고, 이 vector를 다시 디코딩하는 과정으로 번역을 진행한다.
인코딩 네트워크와 디코딩 네트워크는 동시에 훈련되는데 여기서 “고정된 길이의 벡터(fixed length vector)“로 압축해야하는 것은 잠재적 문제이다. 이는 학습된 corpus 문장보다 긴 문장을 처리하기 힘듦을 의미한다. 실제로 조경현 교수님의 논문에서 이러한 성능 저하를 보여주고있다.
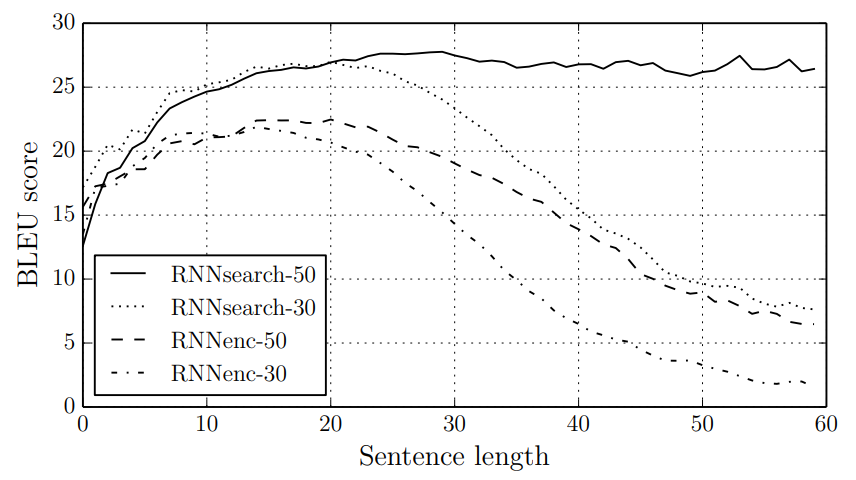
- 실제로 문장의 길이가 길어질수록 BLEU 스코어가 급감함을 볼 수 있다. 학습에 사용된 코퍼스의 수 역시 짧을 수록 더 성능이 안좋음을 볼 수 있다.
논문에서는 이러한 단점을 극복하기 위해 제안된 방법으로 soft-alignments(이하 attention) 작업을 진행한다.
Soft-alignment와 Hard-alignment의 차이
- hard-alignment(attention)는 시계열의 순서 그대로 1:1로 매핑하여 해석하는 방식. 어순이 다른 두 언어를 인식하지 못한다.
- soft-alignment(attention)는 정보를 ‘모두’ 확인하며 어순이 달라도 학습을 통해 인식함을 의미한다. 이하 attention으로 표현한다.
3. Learning to align and translate
앞서 간략히 언급했듯이 인코더에는 Bidirectional RNN을 사용함으로써 앞으로 나올 문장 및 단어는 물론이고, 이전에 나왔던 단어까지 모델에 반영한다. 디코딩에는 attention layer를 통해 번역될 소스 문장을 찾는다.
네트워크에 대한 설명은 다음 수식들로 간략하게 설명하고 넘어가겠다.
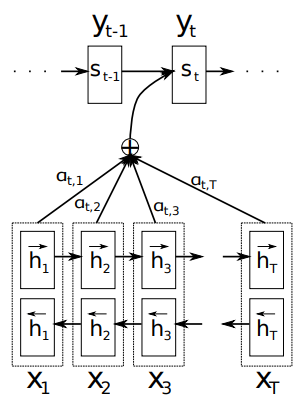
Bidirectional encoder에서 hidden states 벡터 \(h\)는 순방향 벡터 \(\overrightarrow{h_j^\top}\)와 역방향 벡터 \(\overleftarrow{h_j^\top}\)를 concatenate하여 구한다.
다음으로, alignment model \(e_{ij}\)는
\[e_{ij} = a(s_{i-1}, h_j) = v_a^\top\text{tanh}(W_as_{i-1} + U_ah_j)\]이고, 이때 \(W_a\)와 \(U_a\) 그리고 \(v_a\)는 weight matrices이다.
이렇게 구한 \(e_{ij}\)의 각각의 확률값으로부터 그 비율을 계산하여 weight 값인 \(\alpha\)를 구한다.
\[\alpha_{ij} = \frac{exp(e_{ij})}{\sum^{T_x}_{k=1}exp(e_{ik})}\]이 weight들과 hidden state의 weighted sum인 Context vector \(c_i\)를 계산한다.
\[c_i = \sum^{T_x}_{j=1}\alpha_{ij}h_j\]이 i번째 Context vector는 i-1번째의 \(s_{i-1}\)와 \(y_{i-1}\)과 함께 계산되어, 다음 i번째 \(s_i\)를 구하는데 사용된다.
\[s_i = f(s_{i-1}, y_{i-1}, c_i)\]여기서 중요한 점은 context vector의 인덱스에서 확인할 수 있듯이, 매 단어마다 context vector를 구해준다는 점이다. seq2seq 모델은 context vector 값이 상수로 계산된다. 즉, 인코딩이 끝나면 딱 한 번 계산되고, 그 vector로부터 디코딩을 실행하지만, attention은 매 단어마다 다시 계산된다.
이러한 방식으로 계산되는 context vector는 fixed-length로부터 자유롭게 해준다. 가변길이의 문장을 인코딩하여 고정길이의 벡터로 만들고, 다시 디코딩하여 가변 길이 벡터로 만드는 것은 모델의 성능을 저하시킬 수 있다고 논문에서는 주장한다.
4. Experiment
논문에서는 영어와 불어 번역으로 테스트를 했고, 약 348M개의 데이터를 사용하여 테스트를 진행했다.
위 실험 결과에서 RNNenc는 이전 모델이고, RNNsearch는 논문에서 제안한 모델이다. 새로 제안한 모델이 이전 모델과 비교했을 때 더 좋은 성능을 내는 것을 볼 수 있다. 특히, 50개 이상의 단어로 이루어진 긴 문장으로 학습했을 경우에 문장의 길이가 길어져도 성능 하락을 잘 방어하는 모습이다.
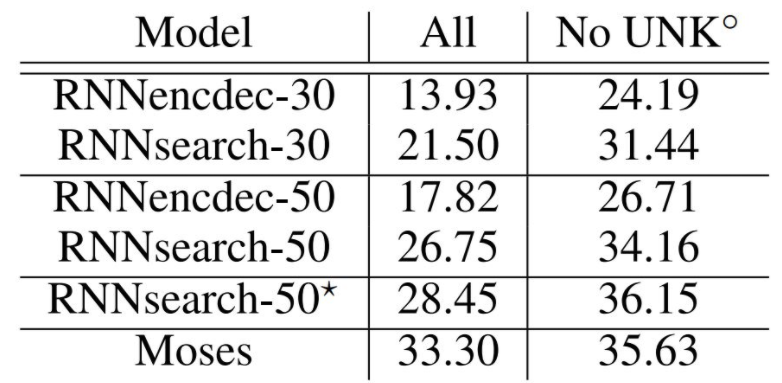
*가 붙은 RNNsearch-50은 긴 시간 동안 학습한 경우인데, SMT(Statistical machine translation)에서 유명한 모델인 Moses보다 좋은 성능을 발휘하는 모습을 확인할 수 있다. (여기서 No UNK\(^\circ\)는 모르는 단어를 제외한 경우를 의미한다.)
추가적인 실험 및 결과는 논문에 자세히 나와있으니 참고하자.