Contents
이번 강의에서는 1강 Image Classification에 이어서 대표적인 CNN 모델들에 대해 배웁니다.먼저 VGGNet과 비슷한 시기에 등장한 GoogLeNet을 시작으로, 지금도 많이 쓰이고 있는 ResNet에 공부하고 실습을 진행합니다. 이 외에도 추가적으로 몇가지 CNN 모델들에 대한 소개를 합니다. 특히, 1강과 3강까지 다룬 4가지 모델 (AlexNet, VGGNet, GoogLeNet, ResNet)에 대하여 메모리 측면과 계산 효율 관점에서 비교 분석을 합니다.
강의에서는 다양한 아키텍쳐를 다뤘다. AlexNet, VGG, GoogleNet을 다뤘는데, 이 세 모델에 대한 내용은 따로 언급하지 않겠다. 그 이유는 앞서 정리했던 포스팅에서 어느정도 언급을 했기 때문에 새로이 자세하게 다루는 ResNet과 그 이후 모델에 대한 내용만을 다룰 예정이다.
또한, 1강과 3강의 Image classification은 사진이 주어졌을 때 사진 전체를 카테고리로 분류합니다. 반면 Semantic Segmentation은 사진이 주어졌을 때 사진 내 각 픽셀을 카테고리로 분류하는 task 입니다. 즉, 하나의 사진이 아닌, 사진에 있는 모든 물체들을 분류한다는 것입니다. 본 강의에서는 먼저 최초의 end-to-end segmentation 모델 FCN을 시작으로 Hypercolumn 모델을 배웁니다. 다음으로 segmentation의 breakthrough라고 볼 수 있는 UNet 모델에 대해 공부하고 Pytorch 코드 실습을 합니다. 끝으로 최근까지 좋은 성능을 보이고 있는 DeepLab v3에 대해 배웁니다.
CNN architectures for image classification
ResNet

- resnet은 2016 CVPR에 등장한 논문으로 residual connection을 처음 등장시킨 논문이다
- 최근까지도 Backbone과 실험을 resnet으로 먼저 할만큼 주요한 논문중 하나이다.
revolutions of depth
- resnet 논문의 주요 연구 성과는 깊은 층쌓기이다.
- 기존에도 연구자들이 많은 노력을 했지만, 층을 깊게 쌓지는 못했다.
- 그 이유는 무엇인지, resnet의 성과가 무엇인지 살펴보자.
Degradation problem
- as the network depth increases, accuracy gets saturated$\Rightarrow$rapidly

- 논문에서는 training error와 test error를 비교하였다.
- 이전까지는 모델 파라미터가 많을 수록 training에러가 더 낮아질 것으로 생각해왔었다.
- 여기서 중요한점은 레이어 56 모델이 레이어20 모델보다 error가 높다는 것이
아니다 - train과 test 모두 일정 에러 아래로 안내려 가고 어느정도 선에서 수렴하는 모습을 보이는데 이것도 중요한 점이 아니다.
- test에서 20층보다 56층짜리가 error가 더 높은데, 이 이유가 overfitting 때문이었다면 train에서 56layer 모델이 20layer 모델보다 더 작았어야 했다.
- 그래서 적어도 학습 데이터에만 국한된 좋은 성능을 보여야만 했는데, 학습데이터에 대해서 56layer가 20layer보다 크다는 것은 아직 학습이 덜 되었다는 것을 의미한다.
- 혹은, 학습이 더될 여력이 있지만, 모델의 한계로 단지 수렴만 시키는 정도로 유지하는 것이다.
- 이 결과가 overfitting에 대하여 counterintuitive한 관찰이었다.
- 본 논문에서 저자들은 이러한 현상의 원인을 overfitting이 아닌
degradation이라는 다른 문제이고, 최적화 이슈로 인해 학습이 잘 안되었다고 결론지었다.
Hypothesis
- plain layer : input $x$에서 $H(x)$로 다이렉트로 학습하는 것은 매우 어렵다고 판단.
- residual block을 도입하여 $x$가 $H(x)$가 되는데 변화하는 정도($H(x)-x$)만큼만을 학습하도록 설계하는 것이 더 학습에 도움이 될 것이라고 가설을 설정하였다.

-
이러한 방식을 구현하기 위해서 오른쪽 그림에서처럼
shortcut connection(skip connection)을 구현하였다.- Use layers to fit a residual mapping instead of directly fitting a desired underlying mapping
- The vanishing gradient problem is solved by shortcut connection
- Don’t just stack layers up, instead use shortcut connection
-
역전파관점에서도 우측 그림에서 $F(x)+x$에서 $x$ 방향으로 역전파가 계산될 때 두 가지 방향으로 흐를 수 있도록 설계를 하였다.- weight layer를 통과할 때 vanishing gradient 현상이 일어나도 identity 방향에서는 살아있기 때문에, 학습 가능한 chance를 얻을 수 있다.
Analysis of residual connection
-
이 같은 residual block이 왜 성능이 좋을까?
-
한 분석 논문에 따르면 $2^n$ 의 경우의 수로 gradient가 지나갈 수 있는 방법이 생기기 때문이라고 한다.
During training, gradients are mainly from relatively shorter paths
Residual networks have $\mathcal{O}(2^n)$ implicit paths connecting input and output, and adding a block doubles the number of paths.- block 하나당 두 가지 방향이 생기기 때문에..
PyTorch code for ResNet

- resnet18을 기준으로 basicblock들을 생성하고, layer의 갯수는 두배씩 [2,2,2,2]로 준다.

- layer는 위와같이 쌓이고, 각각의 layer는 아래와 같이 정의된다.

_make_layer라는 함수를 정의하여 파라미터에 따라 쌓이는 규칙을 정의할 수 있게하고, stride는 계속 2로 두어 공간 해상도를 절반씩 줄여간다. 반면에 채널의 사이즈는 두배로 늘어난다.

- for loop을 통해 블럭을 sequential하게 쌓는다.
- 이렇게 구성해두면 쉽게 관리할 수 있다.

- 마지막에는 linear layer로 마무리한다.
Beyond ResNets
Resnet 이후에도 다양한 시도들이 있어왔다. 이에 대한 case study를 간략이 하고 넘어가자.
DenseNet
-
ResNet에서는 skip connection을 통한 indentity mapping을 추가했다면,
-
DenseNet에서는
Channel 축으로 concatenate를 하도록 설계 되어있다.In the
Dense blocks, every output of each layer is concatenated along the channel axis.- Alleviate vanishing gradientproblem
- Strengthen feature propagation
- Encourage the reuse of features
-
이전의 모든 connection을 이어주는 방식으로 dense하게 설계되어있다.

- 상위 레이어에서도 하위 레이어의 특징을 재참조할 수 있게된다.
- 주의해야할 점은 resnet이
+였다면 Densenet은concatenate라는 점이다.+는 신호를 합치는역할concatenate는 옆으로 단순히 이어붙임으로써 신호는 보존한다. (단, 채널은 늘어난다.)
SENet
- depth를 높이거나 커넥션을 새로하는 방법이 아니라 현재 주어진 activation 간의 관계가 명확해지도록 채널간 관계를 모델링하고 중요도를 파악해서 특징을 attention할 수 있게끔하는 방식이다.
- recalibrate channel-wise responses by modeling interdependencies between channels
- Squeeze and excitation operations(attention을 생성하는 방식은 두 가지가 있다.` )
- squeeze : captureing distributions of channel-wise responses by global average pooling
- global average pooling을 통해 공간정보를 없애고 분포를 구한다(magnitude)
- h와 w를 없애는 방향으로 channel의 평균 정보만을 취합하여 vertor로 만든다.
- Excitation : gating channels by channel-wise attention weights obtained by a FC layer
- 이후 채널간의 연관성을 고려해서 W를 계산하고 attentioning을 한다.
- squeeze : captureing distributions of channel-wise responses by global average pooling
- 이후 다시 rescaling하여 텐서를 재가공한다.(색깔별로 중요도를 의미한다.)

EfficientNet
2019년에 제안된 방식으로, 이전까지는 다음 세 가지 방식 중 하나로 모델의 성능을 개선시켜왔다.

- 위 세 가지 방식 각각은 성능을 좋아지게 한다.
- 하지만 일정 단계를 지나면, saturation이 오게되며 수렴하게 된다.
- EfficientNet은 이 세가지 방식을 적절하게 조합하여 성능을 올리자는 데서 아이디어를 얻는다.
-
그 방식은
Compound scaling이라는 방식이며 아래와 같은 구조로 구현된다.
-
이 방식을 통해 효과적으로 더 좋은 성능의 scaling 방식을 서칭하는데 그 의의가 있다.

- 매우 좋은 성능을 보이는 것을 확인할 수 있다.
- 심지어 Neural architecture searching 계열의 모델보다도 더 좋은 성능을 보이는 것을 확인할 수 있다.
Deformable convolution
- 표준 convolution 외에도 irregular한 convolution이 제안되었다.
- 이렇게 제안되는 이유는 자동차와 같이 형식적으로 고정된 사물이 아닌 물체 내에서도 상대적 위치가 변화하는 사물에 대한 이미지를 위해 제안되었다. (ex. 사람의 팔과 다리 등)
- 특징은 offsets map을 추정하기 위한 branch가 따로 결합 되어있다는 점이다.
- offsets field에 따라서 각각의 weight를 옆으로 벌려주고 이에 맞게끔 activation과 irregular filter를 내적해서 하나의 값으로 도출한다.

- 2D spatial offset prediction for irregular convolution
- Irregular grid sampling with 2D spatial offsets
-
Implemented by satandard CNN and grid sampling with 2D offsets

(a) 기존의 정사각형으로 receptive field를 갖는 반면,
(b) 하나의 점에 대한 시작이 물체 내에 포진되어 있는 것을 알 수 있다. deformable한 shape을 따라서 receptive field를 갖는 것을 알 수 있다.
Reference
- Szegedy et al., Going Deeper with convolution, CVPR 2015
- He et al.,Deep Residual Learning for Image Recognition, CVPR 2015
- Veit et al., Residual Networks Behave Like Ensembles of Relatively Shallow Networks, NIPS 2016
- Huang et al., Densely Connected Convolutional Networks, CVPR 2017
- Hu et al., Squeeze-and-Excitation Networks, CVPR 2018
- Tan and Le,EfficientNet : Rethinking Model Scalinng for Convolutional Neural Networks, ICML 2019
- Dai et al., Deformable Convolutional Networks, ICCV 2017
Semantic segmentation
what is semantic segmentation
semantic segmentation
semantic segmentation은 영상단위로 분류하는 것이아니라픽셀 단위로 categorize하는 분야이다.- 하지만 only care about semantie category. 즉 같은 클래스를 가지는 사물간의 분류는 하지 않는다.
- 여러 대의 자동차 간의 분류 (X), 자동차는 다 같은 자동차(O)
- 같은 클래스여도 다른 사물일때 분류하는 방식 $\Rightarrow$
Instance segmentation

Application
- 의료 이미지
- 자율주행
- 등등..
- object의 간의 클래스 분류를 통해 영상 처리가 쉬워진다.
Semantic segmentation architectures
Fully convolutional Networks(FCN)
- 첫 end-to-end segmentation architecture이다.
- 입력에서부터 끝(출력)까지 모두 미분 가능한 구조로 되어있어서 입력과 출력 pair만 있으면 학습을 통해서 타겟 task를 해결할 수 있는 구조를 의미한다.
- 이전까지는 수작업으로 진행했었다.
- Take an image of an arbitrary size as input, and output a segmentation map of the corresponding size to the input
- 예를들어 alexnet은 flattening을 진행하는데, 입력 해상도가 호환되지 않으면, fc layer를 사용할 수 없었다. 벡터의 길이가 달라지기 때문이다.
어떠한 원리로 semantice segmentation이 가능한지 살펴보기 앞서 우선 Fully connected layer와 Fully convolutional layer의 차이를 알아보자.
- Fully
connectedlayer : output a fixed dimensional vector and discard spatial coordinates - Fully
convolutionallayer : output a classification map which has spatial coordinates

- connected 의 경우 공간정보를 고려하지 않고, fixed dimensional vector가 주어지면, 또 다른 fixed vector로 연산되는 레이어이다.
- 반면에, convolutional 레이어는 입력부터 tensor 형태의 activation map이고, 출력 또한 activation map 형태로 나오게 된다. 보통 1x1 컨볼루션 형태로 구현된다.
Fully connected layer에서의 연산을 조금 더 자세히 살펴보면

- 이전 레이어로부터 activation map이 출력이 되면 이것을 flattening을 통해 일자로 편다.
- 이후 이 벡터를 고정된 형태의 fully connected vector로 만들어준다.
- 이렇게 만들게 되면 영상의 공간정보를 고려하지 않고 섞여버린다.
- 그 이유는 flattening하는 단계에서 이미 map을 Z모양으로 일자로 펴면서 공간정보를 잃고, fixed size vector로 만들면서 다시 뭉게지기 때문이다.
이러한 문제를 극복하기 위해 다음의 방법을 사용한다.

- 각 위치마다 Channel axis 방향으로 flattening을 진행한다. 그렇게 쌓인 벡터 각각에 대하여 fully connected연산을 진행한다.
이는 완벽하게 fully convolutional layer와 동일한 연산이다.
A 1x1 convolution layer classifies every feature vector of the convoltuional feature map

- 채널 축으로 1x1 convolution 커널이 Fully connected layer의 한 웨이트 컬럼이라고 볼 수 있다.
- 즉, 필터 갯수만큼 위치마다 별도로 돌리면 각 위치에서의 결과값을 얻는 것과 다르지 않다.
결론적으로 fully connected layer를 1x1 convolutions로 대체함으로써 입력 사이즈에도 대응할 수 있는 fully convolutional neural network를 만들 수 있게 된다.
- 1x1 convolution layer classifies every featrue vector of the convolutional feature map
- limitation : predicted score map is in a very low-resolution
- why?
- For having a large receptive field, several spatial pooling layers are deployed
- Solution: Enlarge the score ap by upsampling
- input map이 큰 것에 비해 output은 매우 저해상도인 경우가 많다
- stride나 pooling 레이어는 receptive field 사이즈를 키워서 넓은 context를 고려, 더 정답에 가까운 결론을 내리기 위함이다. 하지만 이 방식이 저해상도의 원인이 된다.
- 이를 개선하기 위한 방식으로
upsampling이 고려되었다.
Upsampling
- The size of the input image is reduced to a smaller feature map
- upsample to the size of input image
이미지를 원래 사이즈로 복원하는 작업을 진행한다.

- 스트라이드나 풀링을 제거하면, 작은 activation을 유지하지 못하게 된다. 하지만, 똑같은 수의 레이어를 사용했을 때 영상의 전반적 context를 파악하지 못한다. 그 말인즉슨, 영상을 ‘요약’하지 못한다는 뜻이다. 해상도를 유지하자니 영상의 context를 파악하지 못하고, 요약을 하자니 해상도가 안좋아지는 것이다.
- 따라서 일단은 작게 만들어서 receptive field는 최대한 키워놓고(그래야 성능이 좋다), 그 후에 upsampling을 진행하여 강제로 resolution을 맞춰주는 원리이다.
- 이 같은 upsampling 방식에는 두 가지가 있다.
Transposed convolutionUpsample and convolution
Transposed convolution
Transposed convolution에 대한 내용은 여기에 자세히 나와있으니 참고하길 추천한다.
- input의 모든 element에 필터부분을 붙여서 연산하고, 이것을 반복한다.
- 중첩되는 부분에 대해서는 더해지도록 연산한다.

- 하지만 위와 같은 방식으로 연산을 진행할때 $az + bx$와 같이 중첩이 생기는 부분이 발생한다.
- 이부분을 신경써서 튜닝을 해줘야한다.

Upsample and convolution
위의 blocky한 중첩 문제(Check board artifact 현상)를 해결하기 위해 고안된 방식이다.
- transpose방식은 어설프게 overlapping되는 문제가 발생했다.
- 하나의 레이어로 한방에 처리하려다 보니 이러한 효과를 낳았다.
- 반면에
upsampling방식은 이를 보완하고 골고루 영향을 받게 만든다.- 업샘플링 오퍼레이션은 영상처리에서 많이 쓰이는 interpolation(보간법 : Nearest-neighbor, Bilinear를 많이 사용한다)을 적용하고, 다양한 방식을 사용하여 convolution을 진행한다.
- 이전에는 학습이 불가능한 learnable upsampling을 만들기 위해 convolution 레이어를 적용한다.
다시 FCN으로 돌아와서, 아무리 upsampling을 잘 하더라도 잃어버린 정보를 다시 복원하기란 쉽지 않다.

- 낮은 레이어쪽(좌측)에서는 receptive field 사이즈가 작기 때문에, 국지적이며 디테일하게보고, 작은 차이에도 민감한 경향이 있다.
- 반대로 높은 레이어쪽에서는 해상도는 낮지만, 큰 receptive field를 가지고 영상에서 의미론적인 정보를 많이 포함하는 경향을 가지고 있다.
- 하지만 semantic segmentation에서는 이 두 가지 특징이 모두 필요하다.
이러한 두 가지 특징을 모두 취하기 위해 다음과 같이 퓨전을 하게된다.
- integrates activations from lower layers into prediction
- Preserves higher spatial resolution
- Captures lower-level semantics at the same time

- 위 그림과 같이 중간 단계의 특징들을 합칠수록 큰 도움이 된다는 것을 확인할 수 있다.

- Features of FCN
- Faster
- The end-to-end architecture that does not depend on other hand-crafted components
- Accurate
- Feature representation and classifiers are jointly optimized
- Faster
Hypercolumns for object segmentation
공교롭게도 비슷한 시기에 비슷한 연구가 나왔었는데(Hypercolumn이라는 task) 이 논문의 경우 target task가 semantic segmentation으로 같고, motivation 또한 동일하다. 심지어 1 x 1 convolution을 사용한 것도 동일하다.

- 다른점이 있다면, FCN이 1 by 1 convolutional layer와 FC-layer의 차이를 강조했다면, 낮은 레이어와 높은 레이어의 feature를 융합해서 사용하는 것이 가장 강조되는 파트였다.
Hypercolumnat a pixel is a stacked vector of all CNN units on that pixel- Fine localized information is extracted from earlier layers
- Coarse semantic information is extracted from latter layers
- 아무튼 FCN과 마찬가지로 낮은레이어와 높은레이어의 특징을 합치는 방법을 제시하였다.
- 다만 end-to-end는 아니었고, 물체의 bounding box를 설정한 후 적용하는 방식의 사용법이었다.

재밌는 사실은 FCN의 저자와 동일 년도 동일 학교(UC 버클리)에서 제안된 논문이다. 하지만, 인용 수는 1000번정도로 FCN의 수만회와 비교해서 많이 밀리는 모습을 보여주었다.
U-Net
기본적으로 U-Net의 특징을 살펴보면
- Fully convolutional network이다.
Skip connection이라는 새로운 방식을 제안했다.
Overall architecture

- 입력 image를 몇몇 convolution을 통과시킨 뒤, pooling을 통한 receptive field를 크게하기 위해서 해상도를 낮추는 대신 채널 수를 낮춘다.
- 이를 반복하며 작은 activation map을 구하고 여기에 영상의 정보가 잘 녹아있다고 가정한다.
- 이 과정을
Contracting path라고도 한다.- Repeatedly applying 3 x 3 convolutions
- Doubling the number of feature channels
- Being used to capture holistic context
- 여기까지는 일반적인 Convolution 부분과 크게 다르지 않다.

- 단계적으로 activation map의 해상도와 채널 사이즈를 올려준다.
- 채널 사이즈는 Downsampling 과정에서 같은 층에 있는 채널수와 동일하게 맞춰서 낮은 층에서부터 올라오는 activation map 과 concatenate를 실행해준다.
- 이러한 방식의 경로를
Expanding path라고한다.

- 전체 아키텍쳐는 위와 같이 구현된다.
- 모델의 개요를 보면 activation map의 해상도는 deconv에서 절반씩 줄어들고 upconv에서 두배씩 증가된다.
- 반면에 채널수는 두배씩 늘어났다가 절반씩 줄어든다
- 또한, skip connection이 가능하도록 각 레이어에 대칭되는 반대쪽 레이어의 해상도와 채널수는 호환된다.
- 이 Skip connection의 역할이 낮은 레이어에서의 지역적 특징이 높은 레이어층에 전달되는데 왜 이 같은 효과를 낼까?
- Concatenation of feature maps provides localized information
U-Net의 skip connection을 사용할 때 주의해야할 점
What if the spatial size of the feature map is an odd number?
일단, skip connection을 진행할 때 downsample과 upsample시 동일한 layer 층에서의 feature map의 해상도가 맞아야만 한다. (그래야 concatenate를 할 수 있으니깐)

- 위 이미지처럼 feature map이 홀수일 경우 downsampling과 upsampling 과정에서 혼선이 일어날 수 있다.
- 홀수 feature map이 downsample 될 때에는 보통 홀수로 downsample된다.
- 반대로 upsampling될 때에는 짝수로 올라가게 된다. (단순히 두배를 곱하기 때문에)
- 따라서 이러한 경우 모든 downsampling과 upsmapling은 even number로 작동되게 만들어야한다.
PyTorch code for U-Net
코드를 통해 살펴보면 다음과 같다.

- 편의를 위해
double_conv라는 함수를 정의하고, 이 함수의 역할은 두번의conv2d와ReLU를 거쳐 출력되는 함수이다. - 첫 레이어를 살펴보면 input 채널은 3, output 채널은 64이고, 아래층으로 내려가면 input 채널 64, output 채널 128임을 볼 수 있다. pooling의 경우 maxpooling으로 진행하며
stride를 2로 설정하여 해상도를 절반으로 점차적으로 줄여나가고 있는 것을 확인할 수 있다.- pooling의 stride 값이 해상도를 얼만큼의 사이즈로 줄여나가는지 확인할 수 있는 가장 좋은 방식이다.

- upsampling에는
nn.ConvTransposed2d레이어를 사용했다. 여기서 하이퍼 파라미터에 주의하자.- 가장 밑에서 처음 사용되는 레이어를 ConvTransposed2d 레이어의 파라미터를 살펴보면
stride=2,kernel_size=2임을 알 수 있다. - 이렇게 한 이유는 위에서 언급했던 Check board artifact현상을 방지하기 위함이다.
- 저화질에서 고화질로 확장(stride=2)하며 interpolation을 진행할 때, 픽셀의 간격을 두 칸씩 벌리면서(kernel_size=2) 중첩을 방지하는 것이다.
- 가장 밑에서 처음 사용되는 레이어를 ConvTransposed2d 레이어의 파라미터를 살펴보면
DeepLab
- Deeplab v1(2015)
- Semantic image segmentation with deep convolutional nets and Fully connected
CRFs. ICLR 2015 - CRFs : Conditional Random fields 라는 후처리의 존재
- Semantic image segmentation with deep convolutional nets and Fully connected
- Deeplab v2(2017)
- DeepLab : Semantic image segmentation with deep convolutional Nets,
Atrous Convolution, and Fully connected CRFs. TPAMI 2017. Atrous Convolution(혹은 Dilation convolution 이라고도 부른다.)
- DeepLab : Semantic image segmentation with deep convolutional Nets,
- Deeplab v3(2017)
- Rethinking Atrous Convolution for semantic image segmentation. arXiv 2017.
- Deeplab v3+(2018)
- Encoder-Decoder with Atrous Separable Convolution for semantic image segmentation. ECCV 2018
CRFs(Conditional Random Fields)
CRFs는 일종의 후처리로 사용되는 툴이라고 볼 수 있다.
- 기술적으로 그래프 모델링 혹은 최적화에 대한 내용이 필요하기 때문에, 간단한 컨셉만을 이해하고 넘어가기로 한다.
- 픽셀 to 픽셀의 regular한 grid를 그래프로 본다.
- 이 그래프 모델링을 통해 경계를 잘 찾을 수 있도록 모델링을 한 방식이다.
- CRF post-processes a segmentation map to be refined to follow image boundaries
- 1st row: score map (before softmax) / 2nd row : belief map (after softmax)

- 처음 결과를 뽑고나면 두번째 column의 이미지처럼 blurry한 이미지로 출력된다.
- 이 이유는 출력과 입력의 대조가 없기 때문인데, 이를 위해 출력 스코어 맵과 이미지의 경계를 활용하여 score map이 경계에 잘 들어맞도록 확산을 시켜준다.
Dilated convolution
Atrous convolution이라고도 부르는 이 conv 연산은 Dilation factor만큼 일정 공간을 넣어, kernel elment를 확장하는 방식이다.- 이를 통해 receptive field의 exponential expansion이 가능해진다.
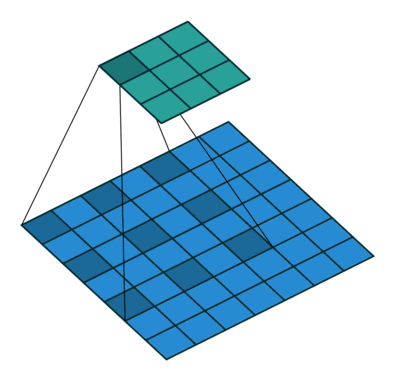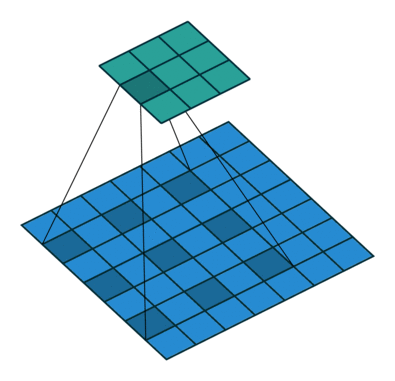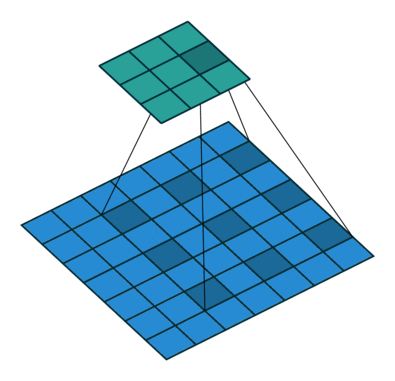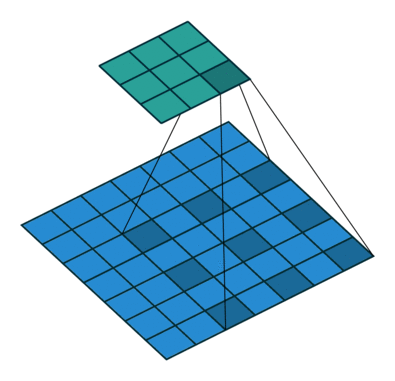
아래는 이러한 Dilated convolution을 잘 표현한 이미지이다.

-
위 그림에서 알 수 있듯, pooling-conv후 upsampling을 하는 것과 dilated convolution(astrous convolution)을 하는 것의 차이를 볼 수 있다. 위 그림에서 볼 수 있듯 공간적 정보의 손실이 있는 것을 upsampling 하면 해상도가 떨어진다. 하지만 dilated convolution의 그림을 보면 receptive field를 크게 가져가면서 convolution을 하면 정보의 손실을 최대화하면서 해상도는 큰 output을 얻을 수 있다.
Astrous separable convolution
DeepLab v3+에서는 semantice 영상의 input resolution이 매우 크기 때문에 Depthwise separable convolution과 앞서 소개한 Dilated convolution을 결합한 astrous separable convolution을 사용한다.
Depthwise separable convolution

- 기존 컨볼루션(좌측)이 하나의 activation 값을 얻기 위해서 kernel 전체가 channel 전체를 내적한다.
- 하지만, Depthwise separable convolution은 이 과정을 둘로 나눈다.
- (우측 1번) kernel과 각 채널(파랑, 초록, 빨강)별로 내적하여 값을 뽑느다.
- (우측 2번) 이렇게 뽑힌 값을 1x1 convolution을 통해서 pointwise하게 하나의 값으로 추출한다.
- 이렇게 하면, 2step으로 계산된 Depthwise separable convolution 방식이 더 복잡한 계산량을 가질 것 같지만 그렇지 않다. 각 방식의 계산량은 아래와 같다.
- Standard conv. : $D_K^2MND^2_F$
- Depthwise separable conv. : $D_K^2MD^2_F+MND^2_F$
- $D_K$ : Kernel size
- $D_F$ : feature map size
- M, N : input, output channels
- 모두 다 비슷한 값을 가진다고 가정할때, 승수를 계산하면 standard의 경우 order 6, depthwise의 경우 order5이다.
DeepLab v3+

- DeepLab v3+의 구조는 위와같다.
- 특이점은 Encoder-Decoder 구조를 따른다는 점과 encoder의 중간에 병렬로
Atrous spatial pyramid pooling을적용한 점이다. 이를 통해 멀티 스케일을 처리할 수 있게 된다. - 이후 concatenate를 통해 feature map을 뽑흔다.
- Decoder에서는 낮은 레이어에서 온
Low-Level feature와 encoder의 Atrous spatial pyramid pooling을 통과한 feature map의 upsampling한 것을 결합하여 segmentation map을 최종적으로 추출한다.
Reference
- Semantic segmentation
- Chen et al., Rethinking Atrous Convolution for Semantic Image Segmentation, arXiv 2017
- Novikov et al., Fully Convolutional Architectures for Multi Class Segmentation in Chest Radiographs, T-MI 2016
- Aksoy et al., Semantic Soft Segmentation, SIGGRAPH 2018
- Semantic segmentation architectures
- Long et al., Fully Convolutional Networks for Semantic Segmentation, CVPR 2015
- Hariharan et al., Hypercolumns for Object Segmentation and Fine-Grained localization, CVPR 2015
- Ronneberger et al., U-Net: Convolutional Networks for Biomedical Image Segmentation, MICCAI 2015
- Chen et al., Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs, ICLR 2015
- Howard et al., MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications, arXiv 2017
- Chen et al., Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation, ECCV 2018
Further Reading