Contents
시퀀스 데이터의 개념과 특징, 그리고 이를 처리하기 위한 RNN을 소개합니다. RNN에서의 역전파방법인 BPTT와 기울기 소실문제에 대해 설명합니다.
시퀀스 데이터만이 가지는 특징과 종류, 다루는 방법, 그리고 이를 위한 RNN(Recurrent Neural Network)의 구조를 앞선 강의에서 배웠던 CNN이나 다른 MLP(Multi Layer Perceptron)와 비교하면서 공부하시면 좋겠습니다.
Sequence Data overview
- 소리, 문자열, 주가 등의 데이터를 시퀀스 데이터로 분류합니다.
- 시점별로 사건이 발생하므로 순서가 매우 중요하다.
- 순서를 바꿨을 때 데이터의 분포가 변화하는 경우 예측분포가 매우 달라진다.
- NOT IID(independent identically distributed)
How to control Sequence DATA?
- 이전 시퀀스 정보를 가지고 앞으로 발생할 데이터의 확률분포를 다루기 위해 조건부확률을 이용할 수 있다.
- 베이즈 법칙을 사용한다
- 위 조건부확률은 과거의
모든 정보를 사용하지만 시퀀스 데이터를 분석할 때모든 과거 정보들이 필요한 것은 아니다. - 시퀀스 데이터를 다루기 위해서는 길이가
가변적인데이터를 다룰 수 있는 모델이 필요하다.
자기회귀모델
- 이때, 고정된 길이 $\tau$만큼의 시퀀스만 사용하는 경우 AR$(\tau)$(Autoregressive Model : 자기회귀모델)이라고 부른다.

잠재AR모델
- 고정된 크기의 vector를 사용했던 앞선 내용과 달리, 바로 이전 정보를 제외한 나머지 정보들을 $H_t$라는 잠재변수(latent vector)로 인코딩해서 활용하는 잠재AR모델이다.

- 이때, $H_t=Net_\theta(H_{t-1}, X_{t-1})$로 표현된다.
- 하지만 이 모델의 문제점은 잠재변수로 어떻게 인코딩하는지에 대한 것이 선택의 문제이다.
- 이를 해결하기 위해 나온 모델이 Recurrent Neural Network이다.
RNN
가장 기본적인 RNN 모형은 MLP와 유사한 모양이다. RNN은 이전 순서의 잠재변수와 현재의 입력을 활용하여 모델링한다.
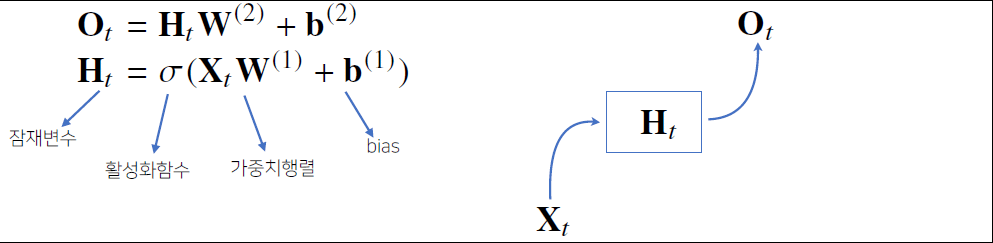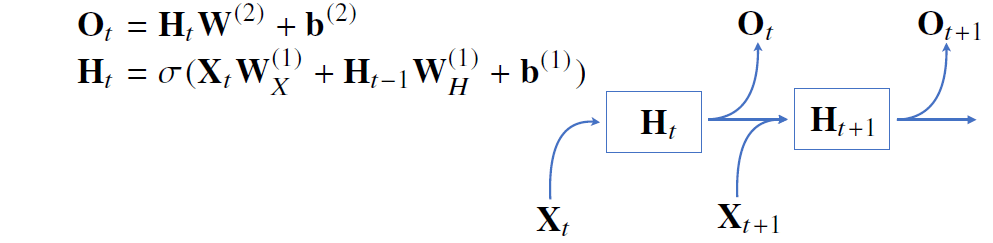
RNN의 역전파는 잠재변수의 연결그래프에 따라 순차적으로 역으로 계산된다.
-
이를 Backpropagation Through Time(BPTT)라고 하며 RNN의 역전파 방법이다.
BPTT
BPTT를 통해 RNN의 가중치 행렬의 미분을 계산해보면 아래와 같이 최종적으로 미분의 곱으로 이루어진 항이 계산된다.

그림에서 보이듯이 해당 항은 시퀀스 길이가 길어질 수록 미분값의 변화 폭이 매우 커지면서 학습이 불안정해진다.
Gradient Vanishing
시퀀스 길이가 길어지는 경우 BPTT가 불안정해지므로 길이를 끊는 것이 필요하다. 이 방법을 Truncated BPTT라고 부른다.
- 예를들어 $X_t$의 gradient를 구할 때, $O_{t+1}$부터 계산되는 gradient를 구하는 것이 아니라 특정 block에서 끊고 $O_{t}$에서 오는 gradient만으로 계산하는 방법이다.

- 하지만 이 방법도 완벽하진 않다. 이를 위해 기본 Vanilla RNN이 아닌,
GRU혹은LSTM구조를 사용한다.
Sequential Models
주식, 언어와 같은 Sequential data와 이를 이용한 Sequential model의 정의와 종류에 대해 배웁니다. 그 후 딥러닝에서 sequential data를 다루는 Recurrent Neural Networks 에 대한 정의와 종류에 대해 배웁니다.
Further Question
- LSTM에서는 Modern CNN 내용에서 배웠던 중요한 개념이 적용되어 있습니다. 무엇일까요?
- Pytorch LSTM 클래스에서 3dim 데이터(batch_size, sequence length, num feature),
batch_first관련 argument는 중요한 역할을 합니다.batch_first=True인 경우는 어떻게 작동이 하게되는걸까요?
Sequential Model
Markov model (first-order autoregressive model)
- MDP(Markovian Decision Property) : 현재의 결과는 바로 직전 과거에만 영향을 받는다.
- 이는 현실의 많은 데이터데 적용되지 않는 모델이다.
Recurrent Neural Networks
RNN 모델은 앞서 언급했으므로 생략하기로 한다.
Long Short Term Memory

LSTM의 구조는 위와 같다. 세부적인 gate에 대한 내용을 살펴보자
Forget Gate

Decide whish information to throw away
어떤 정보를 잃어버릴지 결정한다.
- 현재의 입력 $x_t$와 이전의 output $h_{t-1}$를 input으로 받는다.
- 결국 Sigmoid($\sigma$)를 통과하기 때문에 항상 0~1사이의 값을 받는다.
Input Gate

Decide which information to store in the cell state
정보중에 어떤 것을 올릴지 말지를 결정한다.
- 궁극적으로는 $\tilde{C}$가 현재 정보와 이전 출력값을 가지고 만드는 cell state의 예비군이다.
Update Cell

Update the cell state
\[i_t = \sigma(W_i\cdot\left[h_{t-1}, x_t\right]+b_i)\\ C_t = f_t * C_{t-1} + i_t * \tilde{C}_t\]- forget gate의 output과 input gate의 output을 취합해서 현재 정보 기준으로 새로운 cell state를 업데이트 한다.
Output Gate

Make output using the updated cell state
앞서 설명한 update cell을 이용해 마지막으로 output을 출력한다.
결론적으로 이 네 가지 gate들을 조합하여 LSTM을 구성하게 된다.
Gated Recurrent Unit

Simpler architecture with two gates(reset gate and update gate)
No cell state, just hidden state.
- cell state가 없어짐으로써 output gate가 하나 줄었다. 대신, reset gate와 update gate가 있다.
- 항상 그런 것은 아니지만, 몇몇 task에서 LSTM을 앞서는 모습을 종종 볼 수 있다.
Transformer
이번 강의에서는 지난 강의에서 배운 Sequential model의 한계점과 이를 해결 하기 위해 등장한 Transformer에 대해 배웁니다. Transformer는 Encoder와 Decoder로 구성되어있지만 강의에서는 Encoder와 Multi Head Attention 에 대해 좀 더 집중적으로 배웁니다.
Limitation of Sequential Model
What makes sequential modeling a hard problem to handle?

Transformer
Attention is all you need, NIPS, 2017에서 처음 소개되었다.
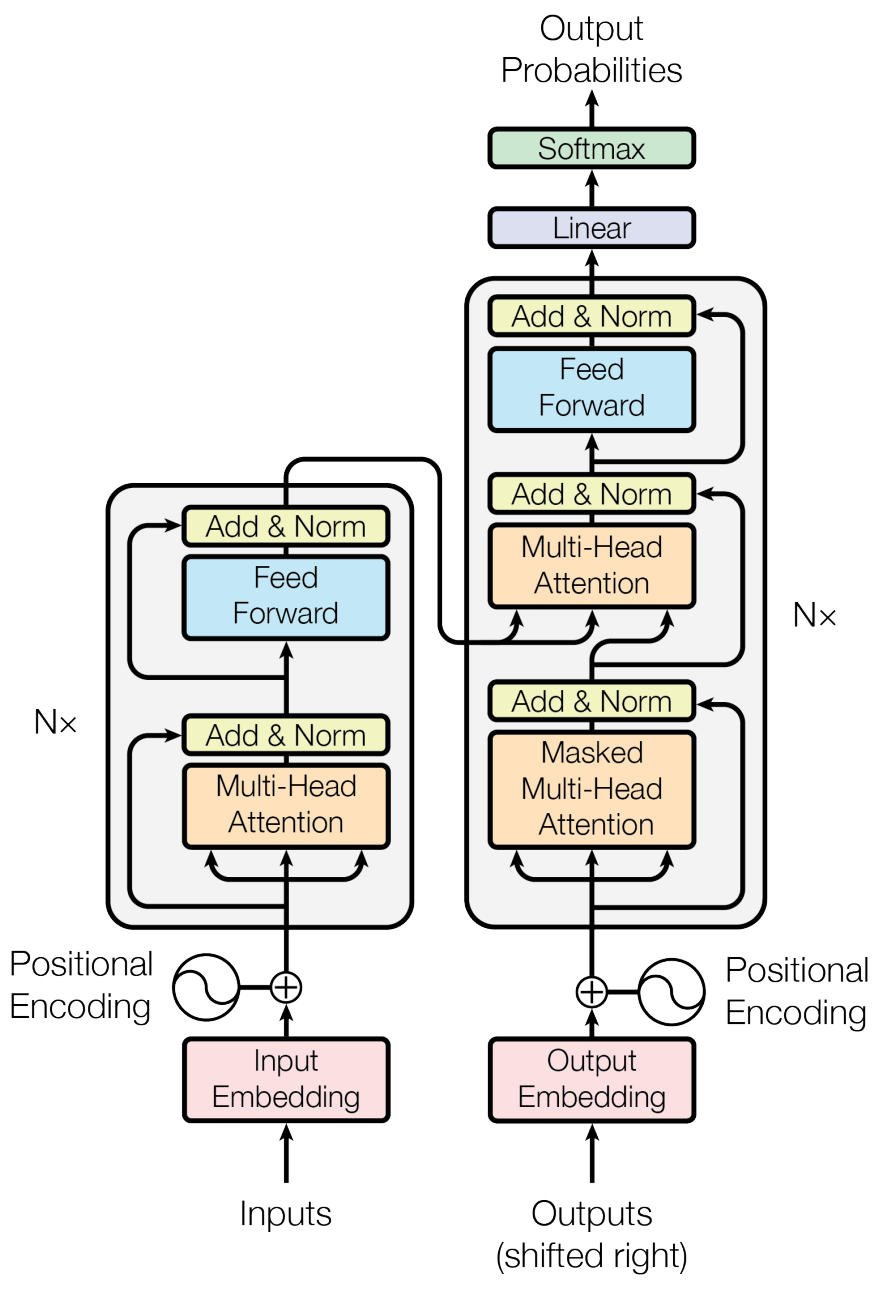
- Transformer is the first sequence transduction model based entirely on attention.
Transformer는 encoding하는 방법론적인 내용이기 때문에 NMT(Neural Machine Translation) 분야에 국한되지 않는다.
트랜스포머에서의 핵심은 3가지이다.
- N개의 단어가 어떻게 한번에 encoder에서 처리되는지
- encoder와 decoder가 어떠한 정보를 주고 받는지
- decoder가 어떻게 generation 하는지
Transformer에 대한 내용은 블로그 따로 포스팅 했으므로 참고하길 바란다.
Vision Transformer
단어를 기반으로 한 NLP Task에만 Transformer 구조를 사용하는 것 뿐만아니라 이미지 도메인에도 사용하기 시작했다.
처음 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale라는 논문에서 발표된 모델이며 2020년 하반기에 발표된 따끈한 논문이다.

해당 architecture는 이미지 Classification task에 사용되었다.
Key Ideas는 다음과 같다.
- 이미지를 패치로 자르고, 해당 순서를 기억하게 하기 위한 Positional encoding과 같은 구조를 사용한다.
- 이를 sequential한 data와 비슷하게 사용하여 classification을 수행한다.
DALL-E
문장을 작성하면 그에 맞는 이미지를 생성해주는 모델이다.
OpenAI에서 개발했으며, Transformer의 decoder만을 사용했다고 한다.
